
之前在使用线上HBase表时,出现了HBase整个表无法访问的问题,这里提供一种思路和解决方案。为了防止泄密,对图片及日志信息中的地址等信息都做了隐藏和打码处理,望知悉。
问题背景
使用Python进行Scan表后,出现了无法访问表的情况
for key, data in table.scan(batch_size=100,columns=scan_columns):
# 数据处理流程上面是当时Scan表的代码,可以看见只是使用的最基本的Scan语句。
线上该表共有13,517,779条数据,占用空间约28.05GB,只分配了2个Region。
当时线上HBase使用的版本为2.0.2
问题现象
线上程序无法访问此表
我们有一个可以访问线上HBase的UI,发现查询表数据504了,最初怀疑是对应程序挂了,但是发现其他人可以正常访问。比对之后,发现表不一样,于是就怀疑某个表有问题了。
事故前期HBase集群有节点重启
联系运维,查看一段时间内的线上报警,发现HBase有个节点挂了,刚刚自动重启了(运维在回家的路上,不便于立即处理)。
HBase Shell提示Region is not online
运维到家后,联系运维进入HBase Shell,进入该表后,发现HBase Shell也无法操作和访问该表的数据。
当时使用HBase Shell访问时,使用了如下命令:
get 'BaikeSolr','1000035a6bb77419'返回了如下错误信息:
COLUMN CELL
ERROR: org.apache.hadoop.hbase.NotServingRegionException: BaikeSolr,0e38e38e,1667548538492.41f95b62cccd5a09907f7ba94a0886eb. is not online on xxxxxxxxxx.xxxxx.com,16020,1658840373926
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:3298)
at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegion(HRegionServer.java:3275)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1414)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.get(RSRpcServices.java:2446)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos\$ClientService\$2.callBlockingMethod(ClientProtos.java:41998)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:131)
at org.apache.hadoop.hbase.ipc.RpcExecutor\$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor\$Handler.run(RpcExecutor.java:304)HBase Master显示的Region个数错误
联系运维进行查看HBase Master上的情况,发现该表的大部分信息已经显示不出来了,界面上的Table Attributes这一栏目也有报错。
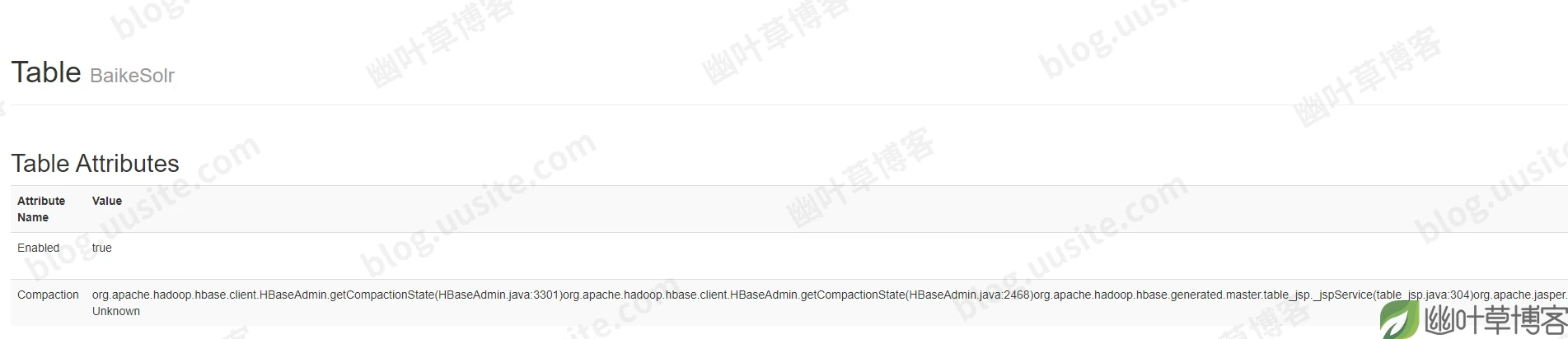

表正常的时候,是这样显示的:

再往下看,可以看到表的Region信息
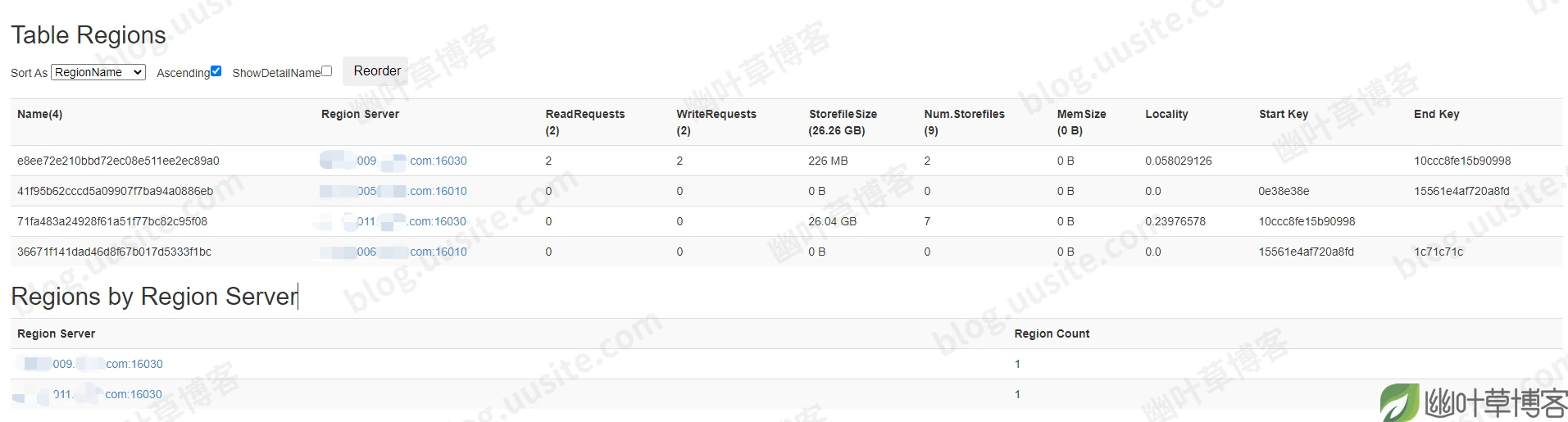
发现有4个Regions,比正常的多了2个。
原因分析
和运维人员进行沟通后,发现表之前发生过一次重建,重建时由于确认过旧表数据是无效的,因此重建的时候是直接执行的truncate命令,导致了原来预分配的19个Region重建后只剩下了2个Region,再结合HBase Master给出的信息进行分析,由于这个Table之前只有2个Regions,但是其中一个节点挂了之后,在这个界面出现了4个Table Regions,其中只有2个在线,不在线的2个没有Store files,因此怀疑出现了一致性问题,需要进行修复。
因此推断Region个数不足导致了Scan的时候HBase节点挂了一个。HBase自动恢复之后,集群出现了一致性问题了,对表的访问指向了异常的Region,从而导致所有访问都失败了。
经验总结:如果要重建HBase表,直接使用truncate命令是不会保留分区的,如果要保留分区应该使用 truncate_preserve命令。
问题修复
发现是一致性问题后,尝试进行修复,但是HBase版本是2.0.2版本,无法直接使用1.x版本的hbck,HBase2可用的Hbck2已经被独立出去,需要自行编译安装。编译安装好Hbck2后,还需要配置环境变量。
编译安装以及后续配置的教程可以参考官网Readme文件,另外技术博客网上有很多,这里就不赘述了,读者可自行查看相关资料和技术博客。
如果实在发现无法编译成功,也可以尝试直接从官网下载二进制jar包,不过该方式属于铤而走险,不到万不得已别直接在线上环境使用。
运行如下命令扫描表是否存在问题:
hbase hbck -j hbase-hbck2-1.2.0.jar extraRegionsInMeta default:BaikeSolr返回如下结果,说明表存在一致性问题:
Regions in Meta but having no equivalent dir, for each table:
BaikeSolr->
41f95b62cccd5a09907f7ba94a0886eb 36671f141dad46d8f67b017d5333f1bc使用命令进行修复对应的表,该命令会通过删除多余的Regions来修复Meta信息:
hbase hbck -j hbase-hbck2-1.2.0.jar extraRegionsInMeta --fix default:BaikeSolr运行过程中有如下日志打印:
16:16:00.054 [pool-7-thread-1] INFO org.apache.hbase.HBCKMetaTableAccessor - Deleted BaikeSolr,0e38e38e,1667548538492.41f95b62cccd5a09907f7ba94a0886eb.
16:16:00.057 [pool-7-thread-1] INFO org.apache.hbase.HBCKMetaTableAccessor - Deleted BaikeSolr,15561e4af720a8fd,1667548538492.36671f141dad46d8f67b017d5333f1bc.
Regions that had no dir on the FileSystem and got removed from Meta: 2会发现删除了多余的两个Region。
使用命令再次检测表是否存在问题:
hbase hbck -j hbase-hbck2-1.2.0.jar extraRegionsInMeta default:BaikeSolr返回信息如下:
Regions in Meta but having no equivalent dir, for each table:
BaikeSolr -> No mismatching regions. This table is good!到此为止,HBase表的访问恢复正常了,线上程序也可以正常访问此表了。
小结
在这次小事故出现后,由于对HBase不是特别熟悉,和运维两个人有点一筹莫展,差点导致走删表重建重跑数据的道路,因为那个时候和运维两个人都对HBase接触的比较少。联系组长后,决定先等一等,因为表是离线表,把对应的业务停了先,第二天再研究一下。第二天来公司后,看了很多技术博客以及文章,最终和运维两个人一起尝试着把问题解决了。算是有惊无险。也趁着这段时间好好了解一下这些知识。
原创文章,创作不易,版权所有,抄袭必究
作者:幽叶草。如若转载,需要先经过作者同意,并附上原文链接 https://blog.uusite.com/develop/trouble-shooting/138.html
 微信扫一扫
微信扫一扫