
相关现象
- Ambari平台启动HDFS组件失败,报错8020端口拒绝连接
- NameNode启动日志报错:
Unable to determine input streams from QJM和Edit log tailer interrupted. - JournalNode启动日志报错:
Can't scan a pre-transactional edit log
解决方案
- 从NameNode和JournalNode启动日志中的报错信息找出正常的JournalNode节点。
- 从JournalNode启动日志中找到Edit log文件所在目录。
- 备份所有JournalNode节点的Edit log目录。
- 删除异常的JournalNode节点的Edit log目录。
- 将正常的JournalNode节点的Edit log发送到异常的节点中,进行覆盖。
- 重新启动JournalNode和NameNode
问题原因
导致NameNode无法启动的直接原因是 Can't scan a pre-transactional edit log。
而导致 Can't scan a pre-transactional edit log 这个问题的原因是因为磁盘空间不够。
有一个 HDFS 的 Jira 任务 JournalNode error: Can’t scan a pre-transactional edit log。上面有许多人在讨论这个问题,也给出了原因是因为磁盘空间不够。而 Stephen O'Donnell 这个大佬也讲出了磁盘空间不够为什么会导致出现这个问题。感兴趣的话可以去观摩一下。
探索过程
最开始是出现一些项目连接HBase报错,然后去HBase UI和HBase Master上看HBase状态,发现都打不开。
于是进入Ambari平台查看。发现的HDFS出现红点,提示HDFS状态不正常,于是尝试进行启动,结果发现卡死了,
正常来说Start和Stop至少有一个是可以点击的,就像下图这样,但是当时都是灰色的,点击不了。
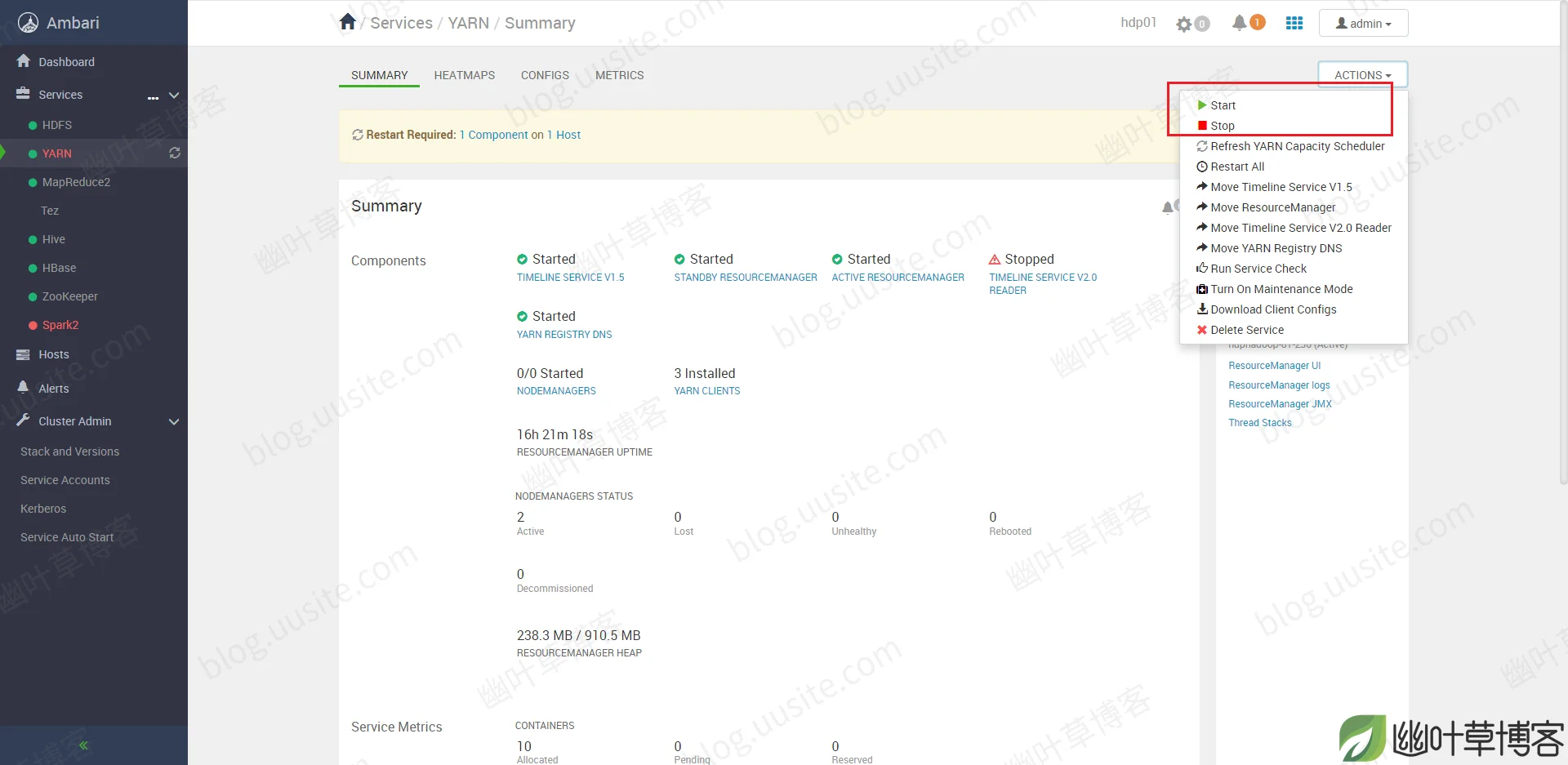

于是进入部署了Ambari节点的系统Linux终端,按顺序停止ambari-agent和ambari-server,然后再按顺序重启ambari-server和ambari-agent(下面的节点上只展示了其中一个机器上执行的命令)。
[root@hdphadoop-81-234 hdpnamenodena]# ambari-agent stop
[root@hdphadoop-81-234 hdpnamenodena]# ambari-server stop
[root@hdphadoop-81-234 hdpnamenodena]# ambari-server start
[root@hdphadoop-81-234 hdpnamenodena]# ambari-agent start重新启动Ambari后,在里面尝试启动NameNode,但是发现一直起不来或者启动成功后依旧无法访问HDFS。遂查看Ambari上的NameNode启动日志情况如下:
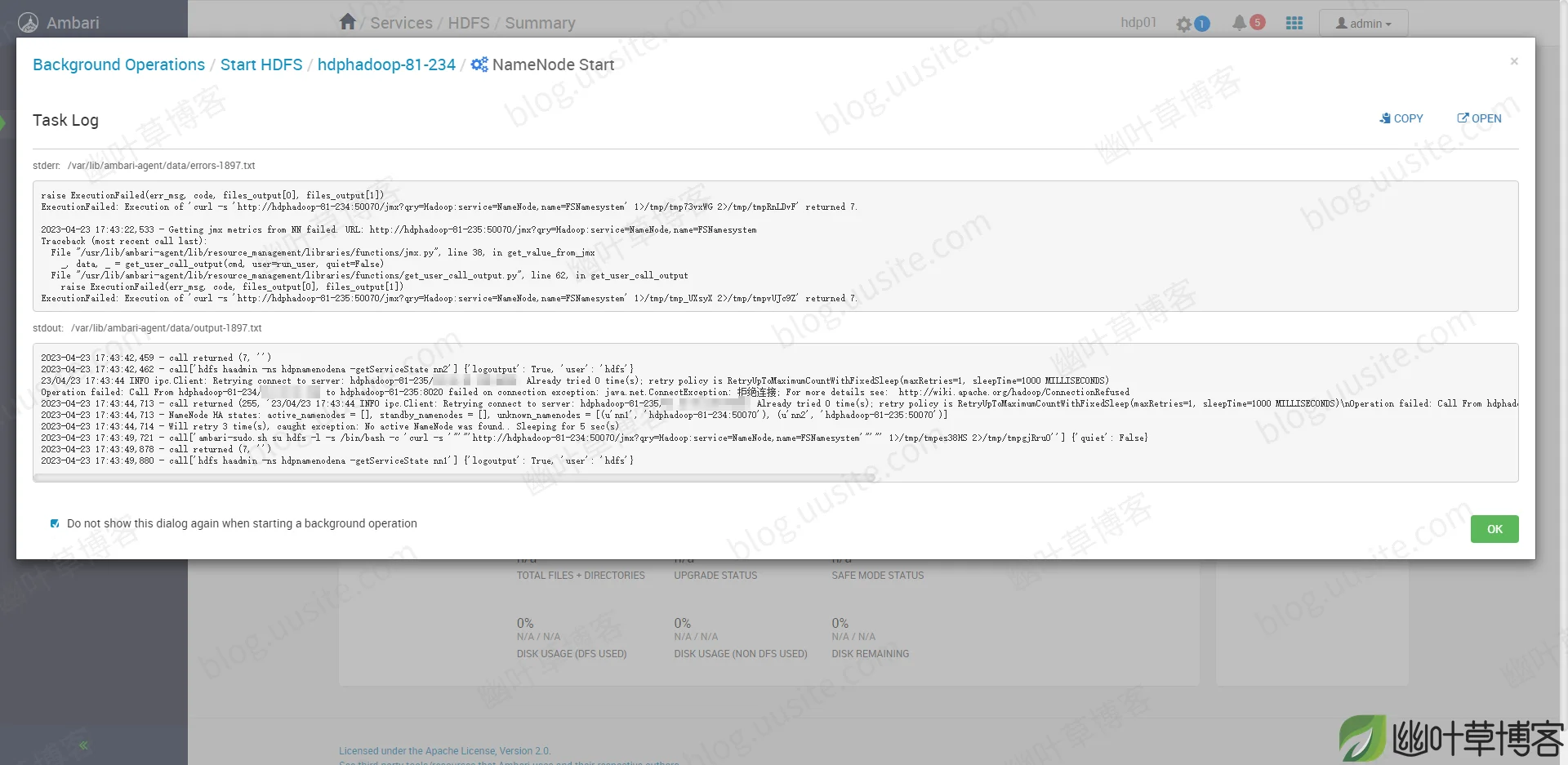
可以看出启动失败的原因是:
23/04/23 17:42:41 INFO ipc.Client: Retrying connect to server: hdphadoop-81-234:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From hdphadoop-81-235 to hdphadoop-81-234:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused查询了一下 Hadoop 组件常用端口号和配置,发现8020端口是NameNode接收Client连接的RPC端口,用于获取文件系统Metadata信息。
尝试使用Telnet命令发现235的的8020端口,发现确实是没有被监听。此时需要通过日志查看NameNode启动失败的具体原因。
可以通过Ambari平台右侧的NameNode Logs进行查看234和235的NameNode日志。
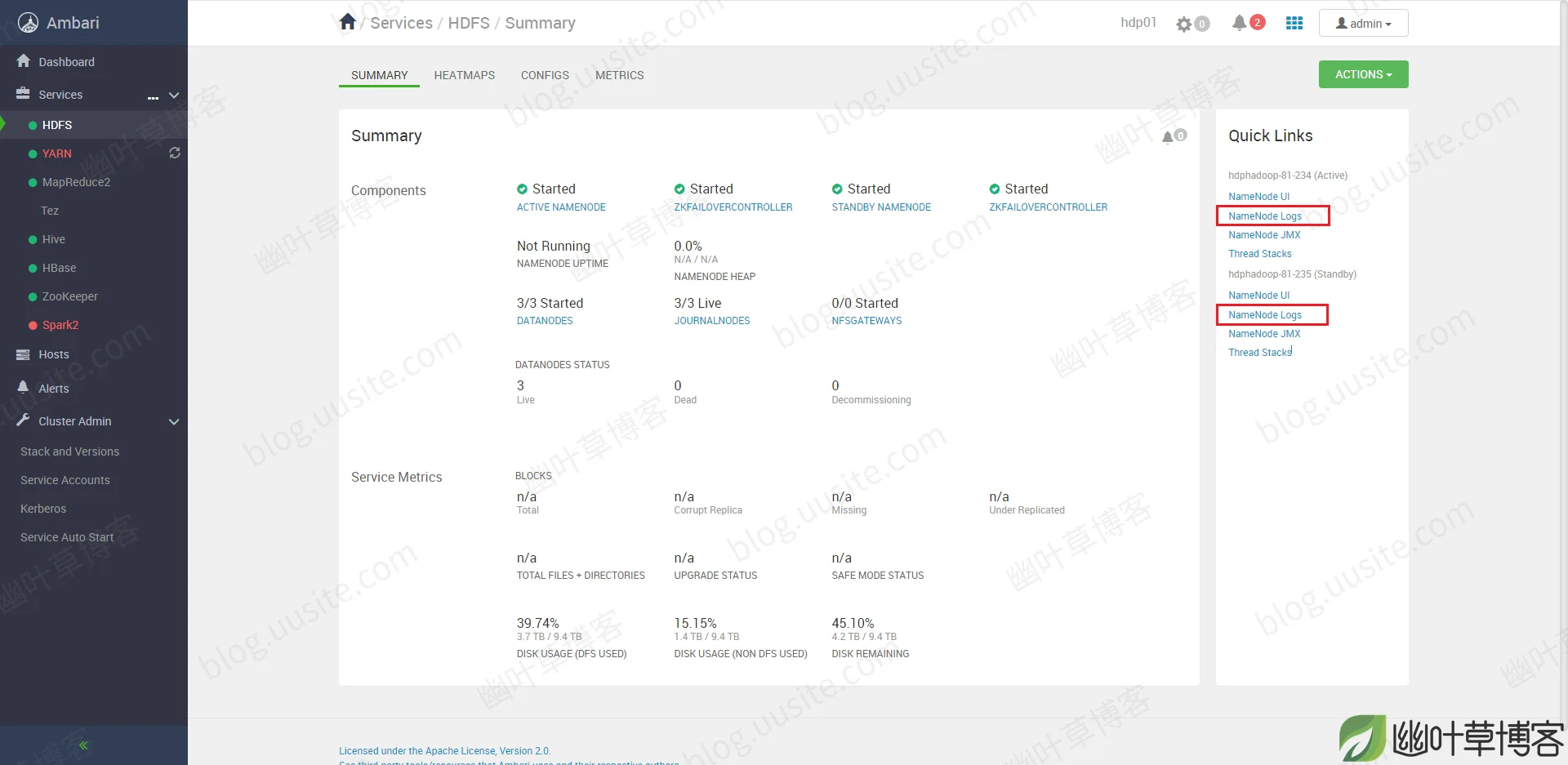
截取的关键NameNode日志报错信息如下:
2023-04-23 16:09:11,423 INFO ipc.Server (Server.java:logException(2726)) - IPC Server handler 3 on 8020, call Call#116 Retry#0 org.apache.hadoop.ha.HAServiceProtocol.getServiceStatus from hdphadoop-81-234:53414
org.apache.hadoop.ipc.RetriableException: NameNode still not started
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.checkNNStartup(NameNodeRpcServer.java:2210)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getServiceStatus(NameNodeRpcServer.java:1737)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.getServiceStatus(HAServiceProtocolServerSideTranslatorPB.java:131)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4464)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:524)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1025)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:876)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:822)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2682)
2023-04-23 16:09:25,462 WARN client.QuorumJournalManager (QuorumCall.java:waitFor(186)) - Waited 14012 ms (timeout=20000 ms) for a response for selectInputStreams. Succeeded so far: [hdphadoop-81-236:8485]
2023-04-23 16:09:26,463 WARN client.QuorumJournalManager (QuorumCall.java:waitFor(186)) - Waited 15013 ms (timeout=20000 ms) for a response for selectInputStreams. Succeeded so far: [hdphadoop-81-236:8485]
2023-04-23 16:09:27,464 WARN client.QuorumJournalManager (QuorumCall.java:waitFor(186)) - Waited 16014 ms (timeout=20000 ms) for a response for selectInputStreams. Succeeded so far: [hdphadoop-81-236:8485]
2023-04-23 16:09:28,466 WARN client.QuorumJournalManager (QuorumCall.java:waitFor(186)) - Waited 17015 ms (timeout=20000 ms) for a response for selectInputStreams. Succeeded so far: [hdphadoop-81-236:8485]
2023-04-23 16:09:29,466 WARN client.QuorumJournalManager (QuorumCall.java:waitFor(186)) - Waited 18016 ms (timeout=20000 ms) for a response for selectInputStreams. Succeeded so far: [hdphadoop-81-236:8485]
2023-04-23 16:09:30,468 WARN client.QuorumJournalManager (QuorumCall.java:waitFor(186)) - Waited 19017 ms (timeout=20000 ms) for a response for selectInputStreams. Succeeded so far: [hdphadoop-81-236:8485]
2023-04-23 16:09:31,451 WARN namenode.FSEditLog (JournalSet.java:selectInputStreams(272)) - Unable to determine input streams from QJM to [hdphadoop-81-236:8485, hdphadoop-81-234:8485, hdphadoop-81-235:8485]. Skipping.
java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:137)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.selectInputStreams(QuorumJournalManager.java:485)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.selectInputStreams(JournalSet.java:269)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1672)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1705)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer.doTailEdits(EditLogTailer.java:299)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.doWork(EditLogTailer.java:460)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.access$400(EditLogTailer.java:410)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread$1.run(EditLogTailer.java:427)
at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:482)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.run(EditLogTailer.java:423)
2023-04-23 16:09:31,453 INFO namenode.FSNamesystem (FSNamesystemLock.java:writeUnlock(282)) - FSNamesystem write lock held for 20019 ms via
java.lang.Thread.getStackTrace(Thread.java:1559)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1032)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:284)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:224)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1607)
org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer.doTailEdits(EditLogTailer.java:339)
org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.doWork(EditLogTailer.java:460)
org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.access$400(EditLogTailer.java:410)
org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread$1.run(EditLogTailer.java:427)
org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:482)
org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.run(EditLogTailer.java:423)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 20019
2023-04-23 16:09:31,456 INFO namenode.FSNamesystem (FSNamesystem.java:stopStandbyServices(1412)) - Stopping services started for standby state
2023-04-23 16:09:31,491 WARN ha.EditLogTailer (EditLogTailer.java:doWork(482)) - Edit log tailer interrupted
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.doWork(EditLogTailer.java:480)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.access$400(EditLogTailer.java:410)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread$1.run(EditLogTailer.java:427)
at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:482)
at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.run(EditLogTailer.java:423)
2023-04-23 16:09:31,505 INFO namenode.FSNamesystem (FSNamesystem.java:startActiveServices(1207)) - Starting services required for active state
2023-04-23 16:09:31,514 INFO client.QuorumJournalManager (QuorumJournalManager.java:recoverUnfinalizedSegments(442)) - Starting recovery process for unclosed journal segments...从上面的结果可以看出来NameNode在执行 selectInputStreams 操作时,需要等待一组 JournalNode 节点的响应。在等待时间超过20秒后,该操作仍未得到一组节点的响应,因此出现了Timed out waiting 20000ms for a quorum of nodes to respond的错误提示。这说明某些 JournalNode 节点无法访问或者出现故障导致操作超时。
于是顺便查看JournalNode的日志,摘取了关键报错信息如下:
2023-04-23 17:29:51,845 WARN namenode.FSImage (FSEditLogLoader.java:scanEditLog(1252)) - Caught exception after scanning through 0 ops from /hadoop/hdfs/journal/hdpnamenodena/current/edits_inprogress_0000000000090500788 while determining its valid length. Position was 1028096
java.io.IOException: Can't scan a pre-transactional edit log.
at org.apache.hadoop.hdfs.server.namenode.FSEditLogOp$LegacyReader.scanOp(FSEditLogOp.java:5264)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.scanNextOp(EditLogFileInputStream.java:243)
at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.scanEditLog(FSEditLogLoader.java:1248)
at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.scanEditLog(EditLogFileInputStream.java:327)
at org.apache.hadoop.hdfs.server.namenode.FileJournalManager$EditLogFile.scanLog(FileJournalManager.java:566)
at org.apache.hadoop.hdfs.qjournal.server.Journal.scanStorageForLatestEdits(Journal.java:210)
at org.apache.hadoop.hdfs.qjournal.server.Journal.<init>(Journal.java:162)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:102)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:147)
at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.getEditLogManifest(JournalNodeRpcServer.java:226)
at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.getEditLogManifest(QJournalProtocolServerSideTranslatorPB.java:228)
at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:27411)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:524)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1025)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:876)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:822)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2682)
2023-04-23 17:29:51,845 WARN namenode.FSImage (FSEditLogLoader.java:scanEditLog(1257)) - After resync, position is 1028096在JournalNode日志中,可以看到错误原因为Can't scan a pre-transactional edit log.,表示不能扫描pre-transactional类型的Edit log文件。这里很明显就可以看出是Edit log出问题了。edit log文件记录了HDFS的写操作,用于支持系统恢复。他如果出问题了,会影响到NameNode和JournalNode的启动。
再想查看更多日志的时候,发现由于NameNode启动失败,Ambari界面上的日志接口无法访问了。只能进服务器查看日志了。但是尴尬的是翻遍了目录都没有找到namenode的日志存储在哪。
找过了默认的/var/log/hadoop/hdfs里面只有gc日志,没有NameNode和JournalNode日志,Ambari上的HDFS的hdfs-log4j设置中也没有设置和日志相关的参数。
那说明参数可能写在启动命令上了。于是在Ambari界面上再次尝试启动NameNode节点,然后立即在对应的服务器上进行查看NameNode的相关进程,果然找到了一堆路径。
寻找日志文件
[root@hdphadoop-81-234 ~]# ps -ef | grep hadoop | grep namenode
hdfs 17732 1 4 4月23 ? 05:09:10 /home/ambari/jdk1.8.0_281/bin/java -Dproc_namenode -Dhdp.version=3.1.4.0-315 -Djava.net.preferIPv4Stack=true -Dhdp.version=3.1.4.0-315 -Dhdfs.audit.logger=INFO,NullAppender -server -XX:ParallelGCThreads=8 -XX:+UseConcMarkSweepGC -XX:ErrorFile=/data/log/hadoop/hdfs/hs_err_pid%p.log -XX:NewSize=256m -XX:MaxNewSize=256m -Xloggc:/data/log/hadoop/hdfs/gc.log-202304231928 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -Xms2048m -Xmx2048m -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT -XX:OnOutOfMemoryError="/usr/hdp/current/hadoop-hdfs-namenode/bin/kill-name-node" -Dorg.mortbay.jetty.Request.maxFormContentSize=-1 -Dyarn.log.dir=/data/log/hadoop/hdfs -Dyarn.log.file=hadoop-hdfs-namenode-hdphadoop-81-234.log -Dyarn.home.dir=/usr/hdp/3.1.4.0-315/hadoop-yarn -Dyarn.root.logger=INFO,console -Djava.library.path=:/usr/hdp/3.1.4.0-315/hadoop/lib/native/Linux-amd64-64:/usr/hdp/3.1.4.0-315/hadoop/lib/native/Linux-amd64-64:/usr/hdp/3.1.4.0-315/hadoop/lib/native -Dhadoop.log.dir=/data/log/hadoop/hdfs -Dhadoop.log.file=hadoop-hdfs-namenode-hdphadoop-81-234.log -Dhadoop.home.dir=/usr/hdp/3.1.4.0-315/hadoop -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.namenode.NameNode从上面的参数-Dyarn.log.dir=/data/log/hadoop/hdfs可以看出日志目录,从参数-Dyarn.log.file=hadoop-hdfs-namenode-hdphadoop-81-234.log又可以看出namenode的日志文件是hadoop-hdfs-namenode-hdphadoop-81-234.log。进入对应目录后,终于找到了HDFS所有的日志了。
查到日志目录后,发现hdphadoop-81-234和hdphadoop-81-235这两台机器的JournalNode日志都有报错,唯独hdphadoop-81-236这台机器的JournalNode日志是正常的,于是先停掉所有HDFS组件,然后备份一下报错中提示的edit_log文件所在的目录/hadoop/hdfs/journal/hdpnamenodena/current
在所有机器上都执行一下备份命令,这样万一出现误操作还可以恢复现场。
tar -zcvf current.tar.<IP>.gz /hadoop/hdfs/journal/hdpnamenodena/current将236刚刚打包的edit_log文件使用scp传输到出错的234和235节点上,删除234和235节点上原来有问题的/hadoop/hdfs/journal/hdpnamenodena/current目录后,解压SCP传过来的压缩包,生成新的current目录:
scp current.236.tar.gz root@hdphadoop-81-234:/hadoop/hdfs/journal/hdpnamenodena
rm -rf /hadoop/hdfs/journal/hdpnamenodena/current
tar zxvf current.236.tar.gz
scp current.236.tar.gz root@hdphadoop-81-235:/hadoop/hdfs/journal/hdpnamenodena
rm -rf /hadoop/hdfs/journal/hdpnamenodena/current
tar zxvf current.236.tar.gz之后在Ambari上重启JournalNode,继续观察日志,发现没有刚刚的报错了。于是继续启动NameNode,也正常启动。
参考链接
原创文章,创作不易,版权所有,抄袭必究
作者:幽叶草。如若转载,需要先经过作者同意,并附上原文链接 https://blog.uusite.com/develop/trouble-shooting/414.html
 微信扫一扫
微信扫一扫